



2023年4月8日~9日,由InForSec、南方科技大学斯发基斯可信自主系统研究院、清华大学网络科学与网络空间研究院、复旦大学软件学院系统软件与安全实验室、国科学院计算技术研究所处理器芯片全国重点实验室、中国科学院软件研究所可信计算与信息保障实验室、中国科学院大学国家计算机网络入侵防范中心、浙江大学NESA Lab、山东大学网络空间安全学院、百度安全、奇安信集团、蚂蚁集团、阿里安全等单位联合主办的“InForSec 2023年网络空间安全国际学术研究成果分享及青年学者论坛”在南方科技大学成功召开。来自清华大学、复旦大学、浙江大学、北京邮电大学、中国科学院大学等66所高校及科研院所的230余人现场出席会议,900余人通过视频会议系统及直播系统参与了本次论坛。
我们将对会议精彩报告进行内容回顾,本文分享的是南京理工大学教授、博士生导师付安民的报告——《PPA:针对联邦学习的偏好分析攻击》。
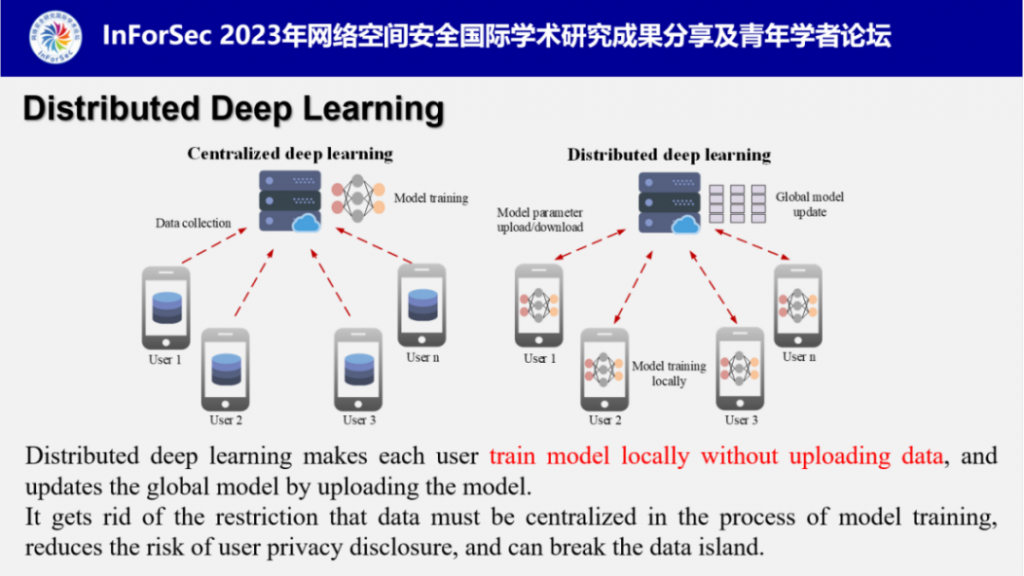
付安民教授首先介绍了分布式深度学习,即联邦学习。联邦学习摆脱了模型训练过程中数据必须中心化的限制,实现了数据的本地操作,允许各方参与者在不交换数据的情况下进行协作,是破解数据隐私保护与数据孤岛难题的新思路,一经提出就成为国际学术界和产业界关注的焦点。
随后,付教授对于目前学术界提出的联邦学习中的主要隐私风险进行了总结,这些研究证明联邦学习环境下依然存在极大的数据隐私风险。
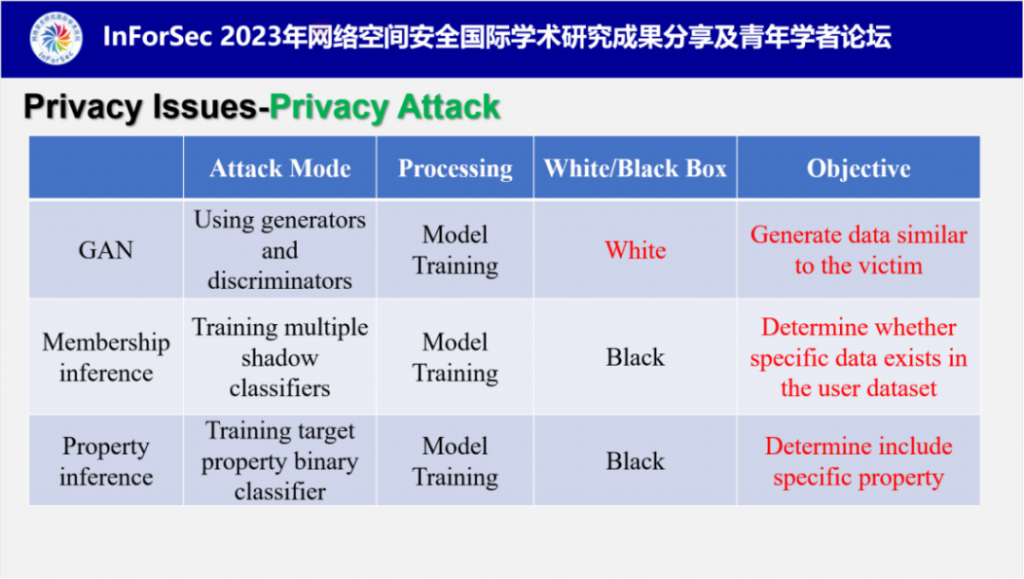
付教授指出现有的针对联邦学习的隐私攻击比如成员推理、属性推理、GAN攻击等,并不能获取有关用户数据分布的隐私信息。而他们最新的研究提出了一种新型隐私推断攻击,成为偏好分析攻击PPA,可以准确地分析出联邦学习本地用户的隐私偏好类别。并且他们设计了一种选择性聚合机制来提升PPA的攻击效率,在隐私相关的任务上对PPA进行了全面评估,尤其是网络购物和自拍分享。

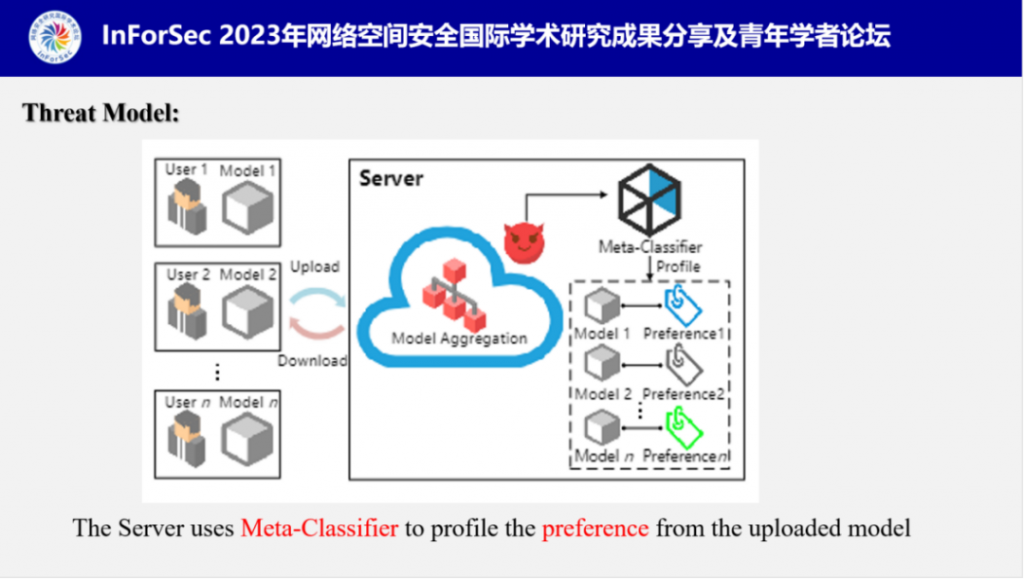
随后,付教授介绍了PPA的攻击模型。服务器作为攻击者对用户发动攻击,目的是通过用户上传的模型分析出对应数据集中的偏好类(数量最多\最少的类别)。
PPA的攻击流程共分为四步,第一步是用户在本地训练模型并上传,第二步是服务器提取每个用户的模型敏感度,第三步是根据事先训练好的元分类器对提取的模型敏感度进行偏好类别分析,第四步是选择性聚合增强PPA的性能。
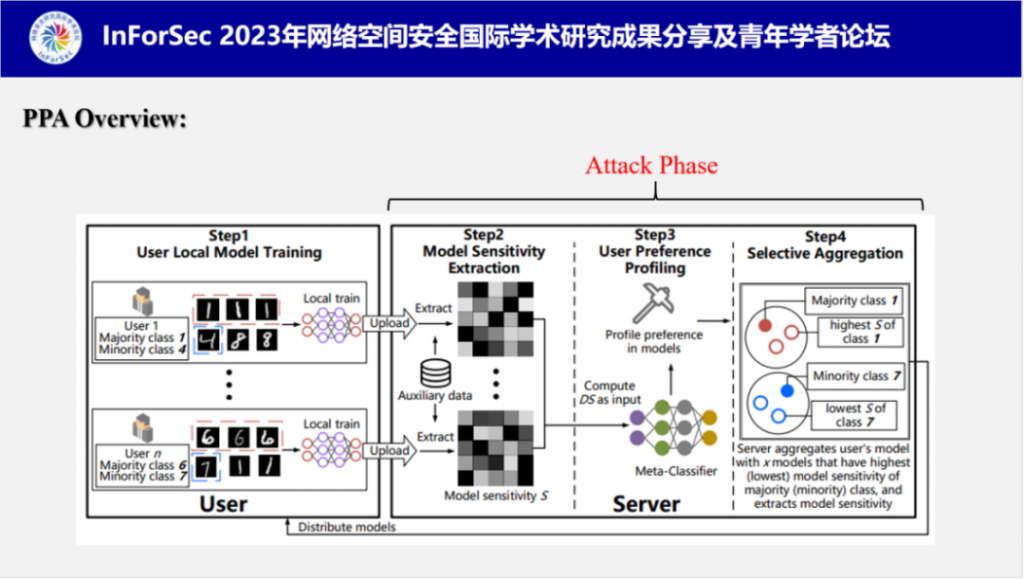
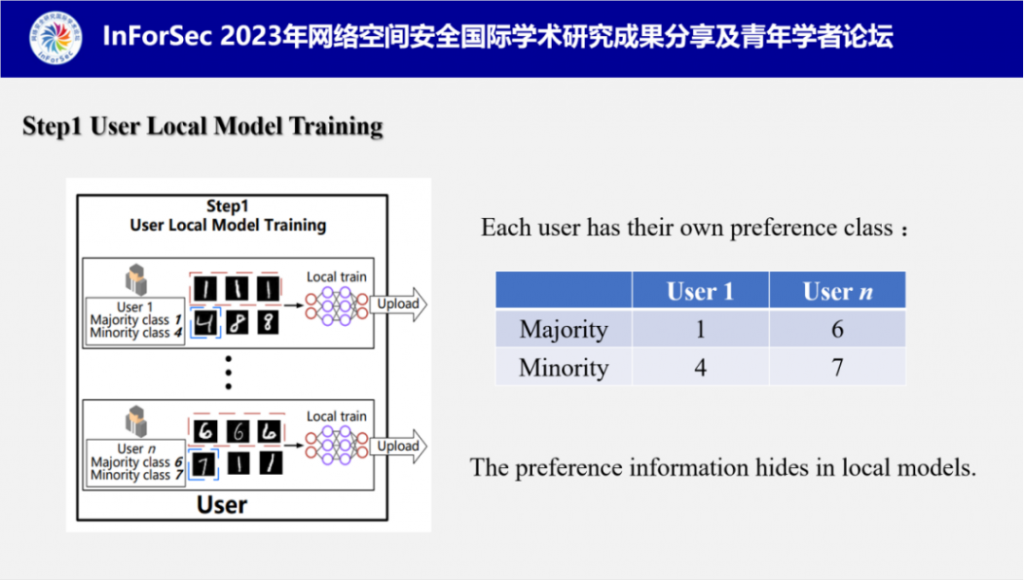
1.用户本地模型训练:联邦学习中,每个用户在本地独立训练模型,在这个过程中,每个用户的训练集都有独自的偏好类别比如图中用户1的最多类为1,最少类为4,用户n的最多类为6,最少类为7。而偏好类别信息会通过训练隐藏在模型中。
2.模型敏感度提取:当服务器获取用户上传的模型后,利用自身的辅助数据集提取模型中每个类的模型敏感度。付教授设计了一个模型敏感度算法,用来表示模型训练过程中的梯度变化。模型敏感度提取算法的展示图如下,从图中可以看出,训练集中类别的样本数越多,模型敏感度越低(左图),样本数越少,模型敏感度越高(右图)。

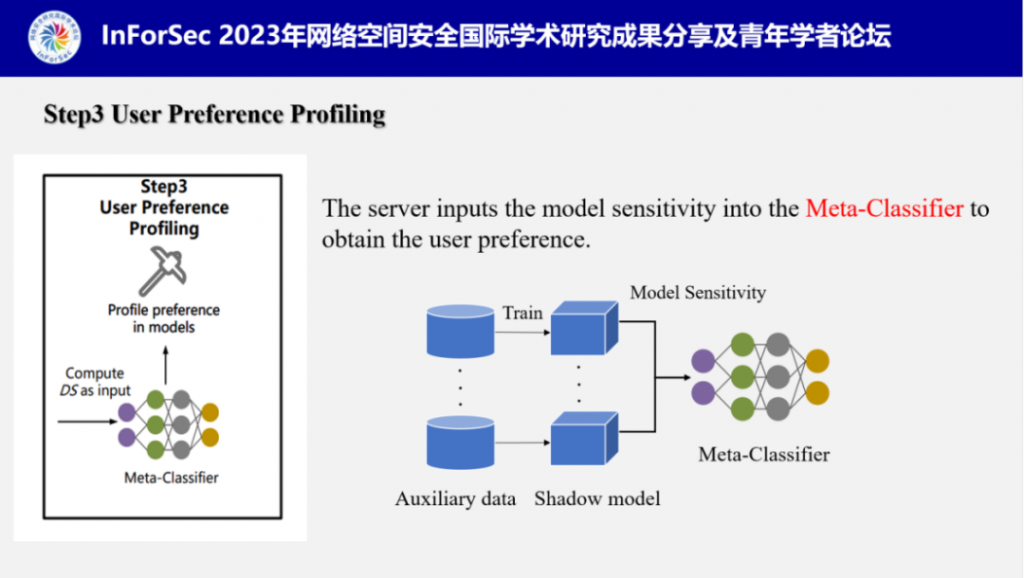
3.用户偏好类推断:当服务器提取完模型敏感度后,便将其输入到事先训练好的元分类器(攻击模型)中,分析出用户偏好类别。下图是元分类器的训练过程,服务器将辅助数据集构建为多个不同的影子数据集,并训练成影子模型,分别提取它们的模型敏感度,利用影子数据集的数据分布和对应的模型敏感度训练元分类器(攻击模型)。
4.选择性聚合:由于传统联邦学习模式下的全局聚合是将所有用户模型进行聚合,这会导致全局模型无法展现用户个体的数据分布,从而混淆偏好类,因此付教授他们设计了选择性聚合机制,将被攻击的用户模型与x个具有与他完全相反偏好的用户模型进行聚合,其余用户依旧采取全局聚合。这个方式可以提高PPA的攻击效果。

紧接着,付教授介绍了他们实验测试所使用的数据集。一共使用了四个数据集,其中后两个是现实世界数据集,分别是商品和人物表情。他们在前两个数据集上进行了PPA的基础测验,用于验证PPA的有效性。在后两个数据集上面对PPA在现实场景中的攻击表现进行了评估,并测试了PPA的可扩展性。

此外,他们针对不同的数据集也设计了不同的模型结构。

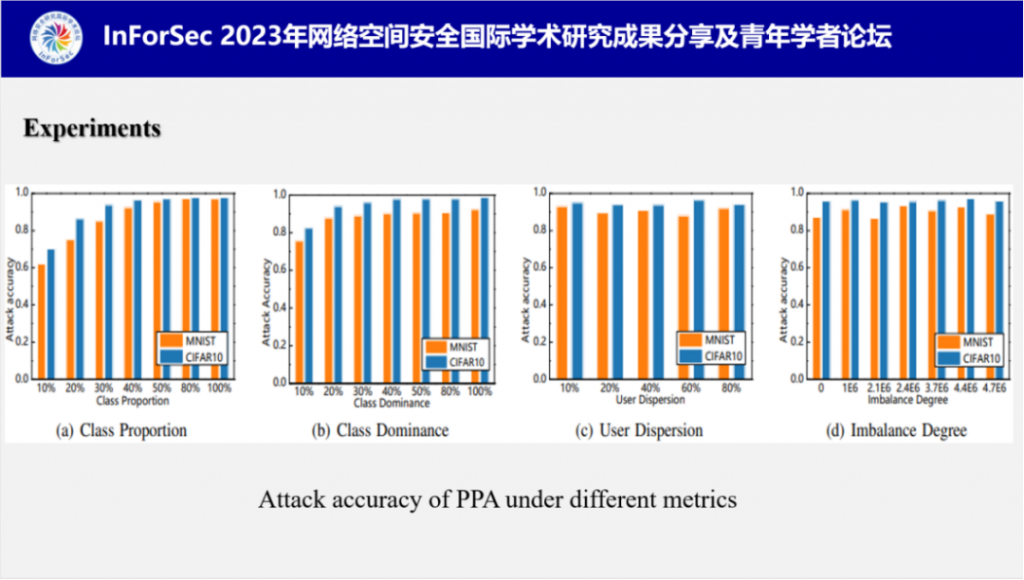
为了全面地还原联邦学习中用户的数据异构性,付教授他们设计了四种数据分布指标:
■ CP:表示每个类别在用户数据集中所占比例
■ CD:表示用户数据集中类别数量的差距
■ UD:表示联邦学习用户偏好类别的差异
■ ID:表示联邦学习用户数据量的差异

在四种数据分布指标下的PPA表现如图所示,从实验结果可以看出在各种数据分布下PPA都可以表现出较高的攻击成功率,证明PPA可以适应具有数据异构性的联邦学习场景。

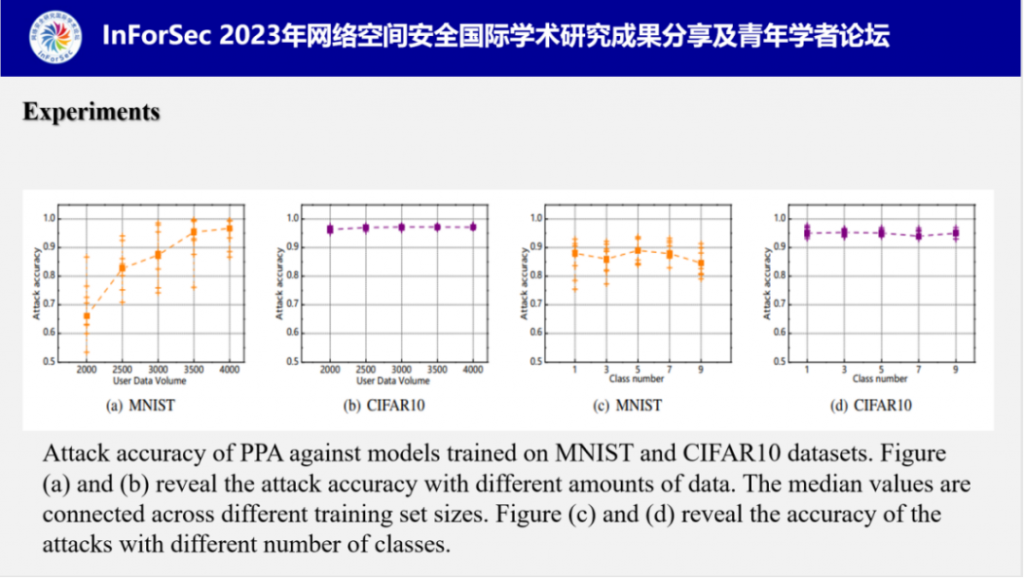
付教授还测试了数据量和类别数量分别对PPA的影响,结果表明样本数量会对攻击产生些微的影响,因为数据本身数据特征不丰富时(如MNIST),当数据特征丰富时对PPA的影响会减弱很多;此外,类别数量对PPA基本上没有影响。
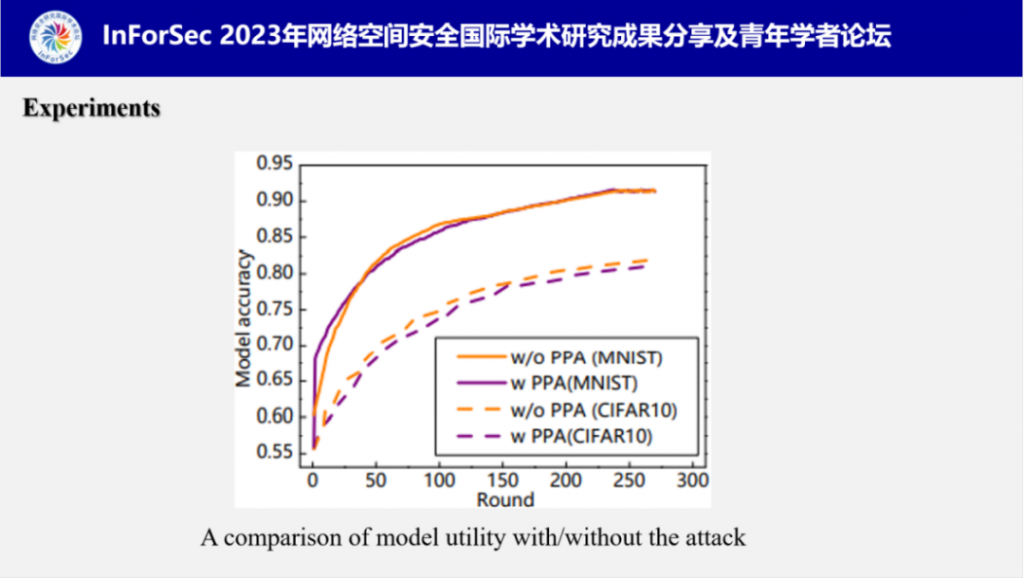
在可用性方面,付教授分别测试了有\没有攻击时的用户模型准确率,结果表明,两者之间并无明显差距,证明PPA并不会影响用户模型可用性。
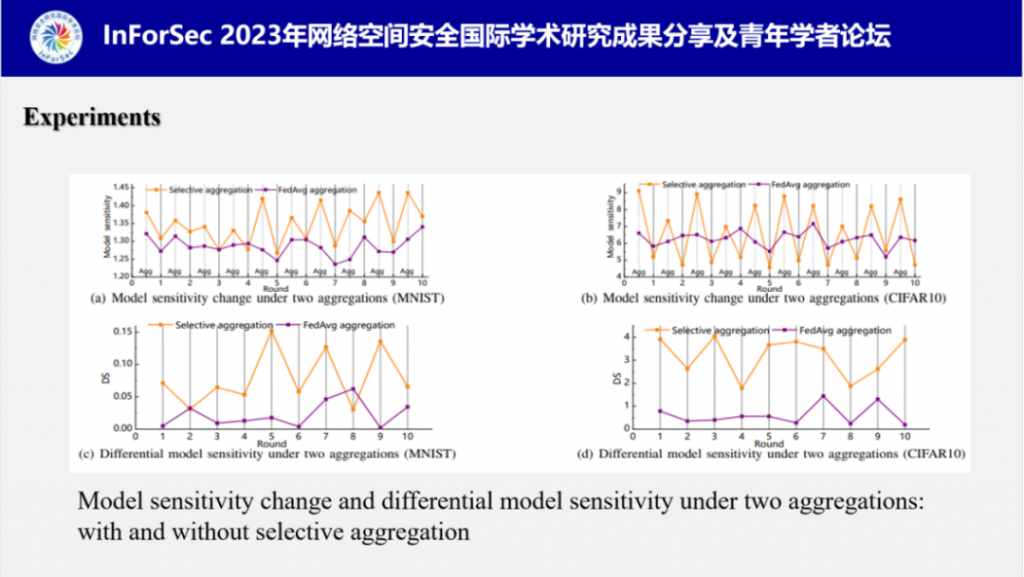
此外,付教授分别测试了选择性聚合和联邦聚合下的模型敏感度变化情况,实验结果表明,他们设计的选择性聚合可以很好地控制模型敏感度变化方向,使之呈现规律的波纹状,反观联邦聚合下的模型敏感度呈现不规律的变化。这会很大程度上影响PPA的效率。
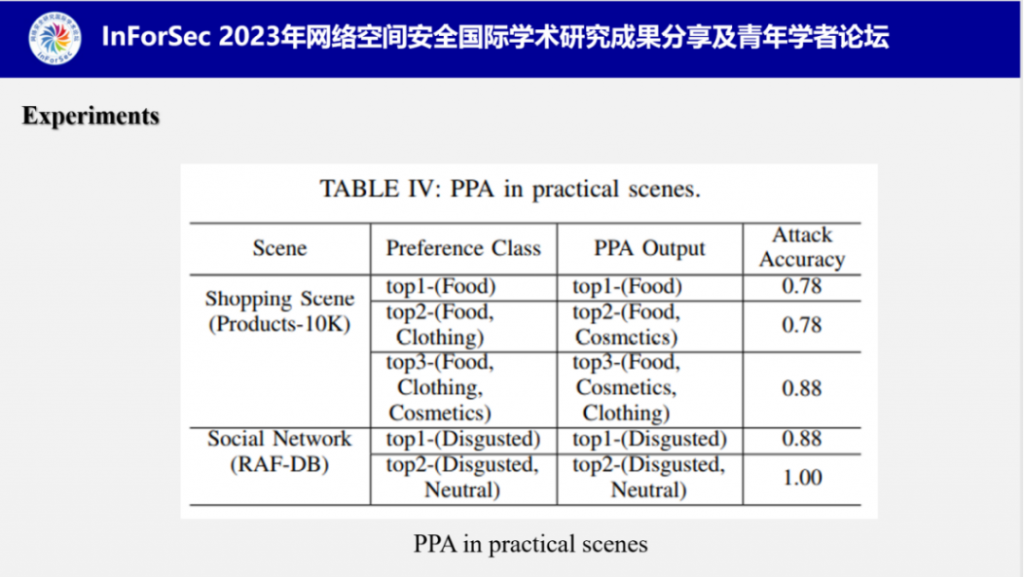
对于PPA在现实场景中的表现,他们模拟了两个场景:购物和社交网络,分别推测顾客最喜爱的商品类型和用户照片中最常见的表情,另外他们扩大了攻击范围,推测top-k个偏好类,即前k个偏好类,实验结果表明PPA在现实场景中具有很优秀的攻击表现。目前的PPA对于top-1的判断是很准确的,但是并不能精确地按顺序推测top-2,top-3。
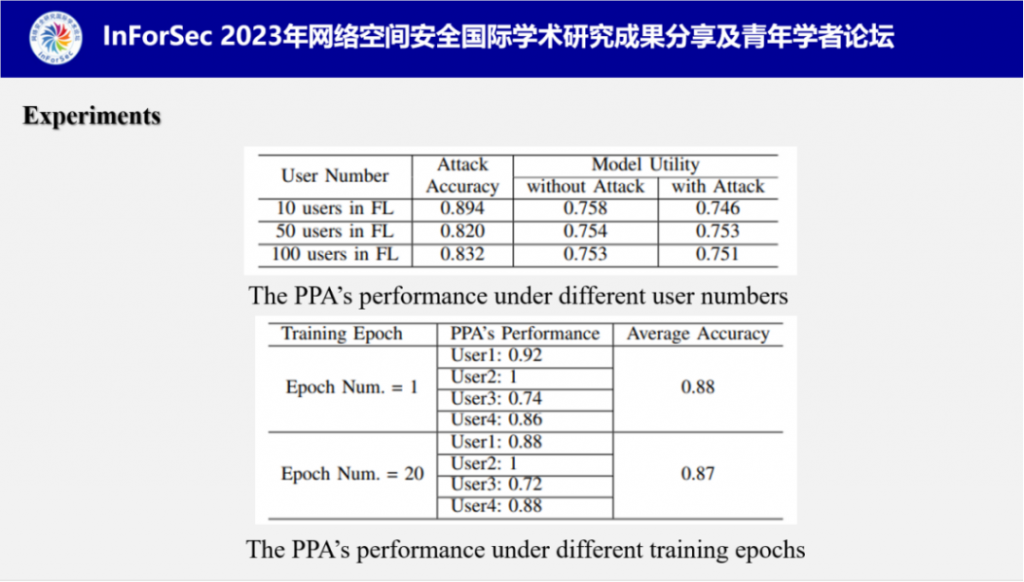
他们还测试了联邦学习中PPA可扩展性相关的几个关键因素:用户数量、用户本地训练轮数,实验结果表明PPA不会受到联邦学习中的因素影响,可扩展性强。
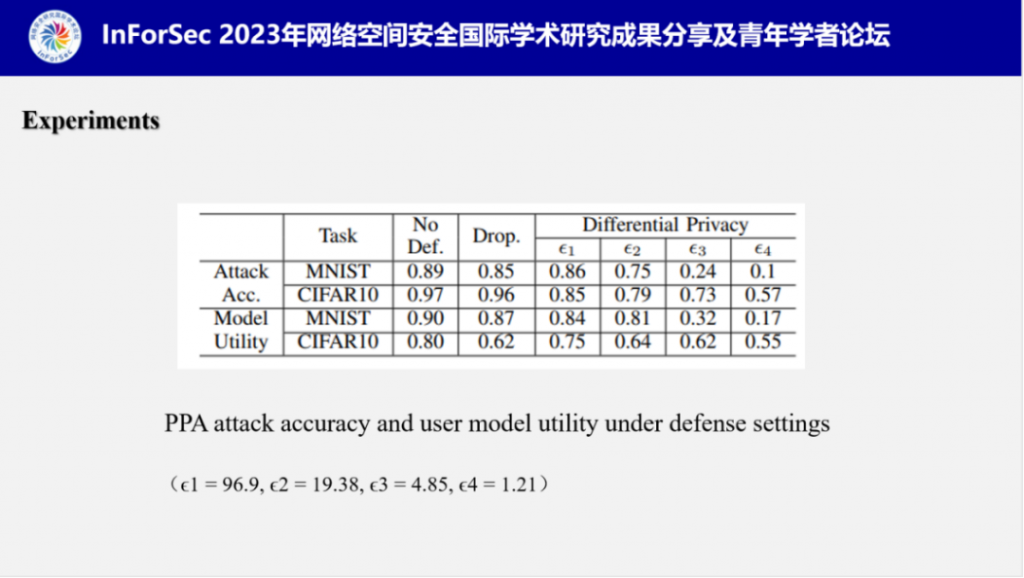
付教授评估了目前主流的几种隐私保护方法:dropout和差分隐私对PPA的抵御能力,实验结果表明,PPA的表现面对dropout时依旧稳定,面对差分隐私时,隐私预算越小,攻击成功率越低,但同时用户模型的可用性也遭受到严重破坏。
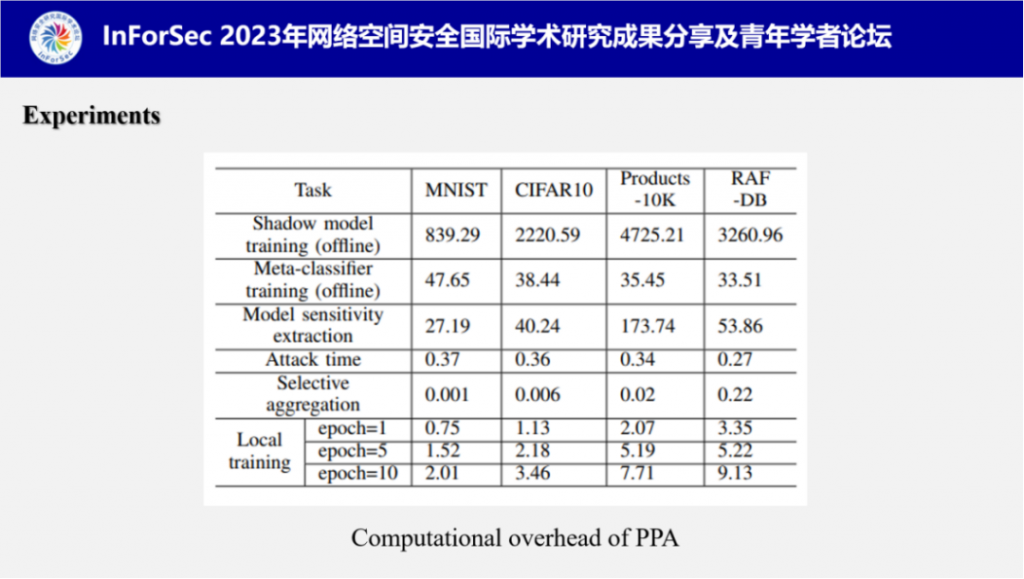
在实验的最后,付教授测试了PPA各项操作的计算开销,可以看出在所有计算开销中影子模型和元分类器的训练是耗时最多的操作,但是这个步骤是在离线阶段进行的,并不会占用攻击时间。
最后,付教授对该研究工作进行了总结。
下载全部PDF,请复制以下地址至百度网盘打开即可:
链接:https://pan.baidu.com/s/1Nqjra8EYl1rBakvffX-uyQ?pwd=pyk4
提取码:pyk4
演讲者简介

付安民,博士,教授,博士生导师,南京理工大学网络空间安全专业负责人,入选江苏省“六大人才高峰”高层次人才和江苏省科技副总。中国计算机学会高级会员,中国计算机学会计算机安全专业委员会委员,中国保密协会隐私保护专委会委员,江苏省网络空间安全学会和江苏省密码学会理事,江苏省网络空间安全学会数据安全专委会副主任,《Security and Communication Networks》期刊编委、《计算机研究与发展》、《信息安全学报》等期刊专辑特邀编委。先后主持国家自然科学基金(3项)等各类高水平课题20多项。
迄今为止,在包括网络与信息安全领域顶会NDSS和顶刊IEEE TDSC、IEEE TIFS在内的著名期刊和会议发表学术论文100多篇(其中ESI高被引论文4篇),获授权国家发明专利27项,制定信息安全领域国家标准4项,获省部级科技奖3项以及南京理工大学教学成果奖特等奖/一等奖2项,指导学生荣获 2022 NIPS 深度学习模型木马检测世界挑战赛亚军以及获全国大学生信息安全大赛和全国密码技术竞赛一等奖4项。




