



董彩芹/文
前言
本文根据原文论文“Fusion: Efficient and Secure Inference Resilient to Malicious Servers”整理撰写,原文发表于NDSS 2023,是暨南大学翁健教授团队与芳禾数据研究团队开展的关于数据安全与隐私计算最新研究成果。
01 研究背景
近几年,由于机器学习的快速发展和在各种场景的普遍应用,机器学习即服务(MLaaS)也开始流行起来并为许多普通用户提供使用机器学习服务的便利。虽然MLaaS带来了巨大的便利,但它也存在隐私泄漏风险。一方面,用户可能将高度敏感数据(例如原始医疗数据)提交到机器学习服务器上,导致隐私泄露;另一方面,服务器用于机器学习服务的模型本身也存在泄漏训练数据集隐私的风险。为了解决上述问题,国内外已经有许多专家进行了深入研究:例如采用同态加密、混淆电路和秘密分享等各种加密技术来实现隐私保护的模型预测,保护服务器模型以及用户输入隐私。但是,使用这些技术实现预测计算的成本很高。为了实现实用且保护隐私的MLaaS,大多数这些工作考虑较弱的威胁模型(即半可信敌手,也称“诚实但好奇”敌手,即假设服务器和用户都会诚实地遵守协议,但是他们也会“好奇”地尝试去推测额外信息)。
02 研究动机
然而,在现实世界中,我们难以保证服务器总是诚实的。真实的情况是服务器可能不如实按照协议执行(例如,服务器返回随机结果来欺骗用户)。此外,即使服务器遵守协议也无法保证其会产生高质量的结果,因为很少有协议可以验证预测结果是否是基于高质量模型产生的。在某些场景下,不准确的结果可能会产生严重后果(例如,MLaaS模型产生的诊断结果将会误导患者)。因此,我们针对以上这种情况提出解决办法,考虑如下图1的MLaaS系统,具体包括以下几种情况:(i)服务器是恶意的(即恶意安全性),其可能会不遵守协议从而导致不正确的结果;(ii)虽然服务器遵守协议,但是使用低质量模型作为输入;(iii)服务器和用户都需要保护各自的输入或者模型的隐私性。
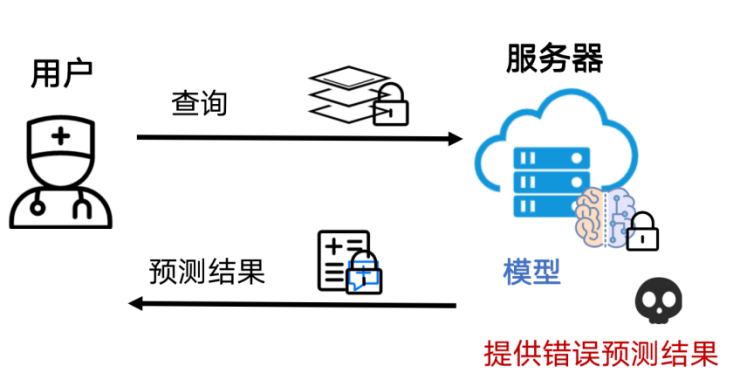
图1. MLaaS系统模型
上述场景可以总结为,在存在恶意服务器的情况下,如何保证模型准确率验证,计算正确性验证和数据(包括用户输入和服务器模型)的隐私性。然而,不幸的是,据我们所知,目前没有研究能同时满足上述三个目标。例如,虽然已有将恶意安全多方计算协议应用在隐私保护机器学习场景中,能够满足计算正确性和隐私性,但是由于恶意安全多方计算协议本身不能验证输入(即模型准确率),因此仅使用这些协议无法强制服务器使用高质量模型作为输入。再比如,尽管可能有一些额外的技术可能被用来验证模型准确率,但是它们的计算开销通常会比较大(例如零知识证明)。总而言之,在神经网络预测中高效地实现上述所有三个目标非常具有挑战性。
03 研究思路
我们旨在提出一种同时满足以上三个安全需求(包括模型准确率验证、计算正确性和隐私保护)的MLaaS解决方案。根据直观分析,可能有多种途径来实现上述需求。例如,我们可以直接将恶意安全的两方计算协议(2PC)应用到神经网络预测中来保证隐私性和计算正确性,但是仍需要额外的技术(例如零知识证明)来验证模型的准确率,因此这种解决方式的开销较大。或者,可以对现有的高效半可信安全预测协议进行修改,以实现恶意安全。但是,这些方案通常也会同时使用多种加密技术,例如同态加密和秘密分享等,同样会造成大量的计算开销。因此如何有效地满足上述三个需求(特别是实现对模型准确率的验证可能需要较多工作)非常具有挑战性。
幸运的是,通过观察到MLaaS场景中一个重要的特性,我们克服了上述挑战,并在不使用零知识证明等高成本技术的情况下以高效的方法同时实现了上述三个安全需求。具体来说,我们观察到在机器学习场景中,用户可以提前知道某些输入(即查询样本)的计算结果(公开样本的标签)。我们的想法是,如果用户能够提前知道一些输入对应的输出,就可以利用这些预备知识同时验证计算正确性和模型准确率,因为如果服务器不遵守计算协议或使用低质量模型作为输入,用户可以通过比较预期的输出(事先已知)与实际输出来发现异常。
04具体方案
基于上述重要发现,我们定制了一种混合结合后验(mix-and-check)的方法,可以同时实现对模型准确率和计算正确性的验证。我们的想法是让用户将一组公开样本与要查询的样本混合在一起,并将它们用作执行隐私保护预测的输入。如果服务器试图欺骗用户且不被其察觉,则服务器必须为某个查询样本的所有副本提供不正确但一致的结果。由于服务器并不知道查询样本和公开样本是如何按照我们的设计混合的,因此用户很容易以极高的概率发现服务器试图欺骗的恶意行为,这样服务器就很难作弊成功。如果用户观察到任意不一致的输出结果(例如,这些公开数据的实际结果不等于其预期结果,或者某个查询样本的多个副本对应的预测结果存在不一致的情况),就说明服务器没有诚实地使用高质量模型作为输入或者没有遵守指定预测协议完成计算。通过这种新型的方式,这些公开样本用于同时验证模型准确率和计算正确性。
如下图2所示,Fusion主要包括三个流程:(i)混合数据集生成;(ii)隐私保护的模型预测执行过程;(iii)模型准确率和计算正确性验证。
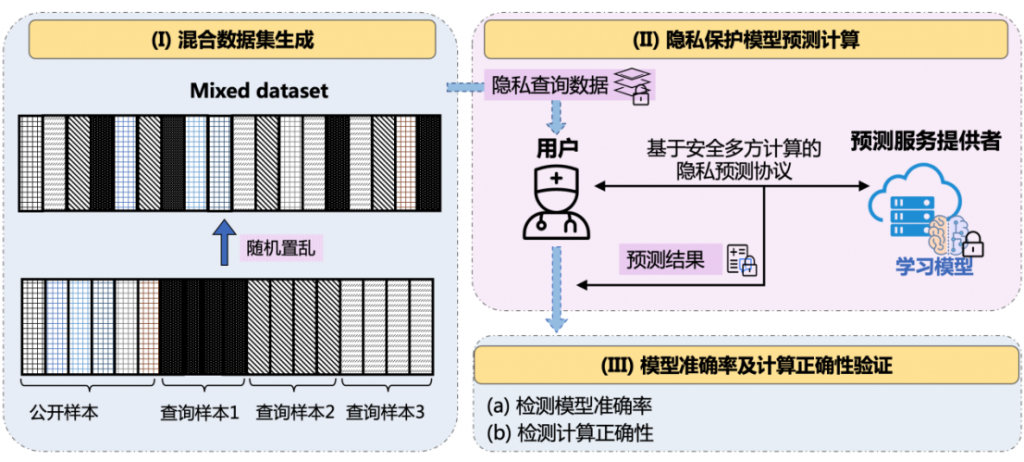
图2.方案流程
(i)混合数据集生成: 在此阶段,用户在本地准备一个混合数据集。用户拥有R个查询样本,把每个查询样本复制相同的B份,并同时准备T个与查询样本相同类型的公开样本。接下来,用户使用随机选择的置换来随机排列所有公开样本以及所有查询样本的副本。
(ii)隐私保护的模型预测执行过程:在这个阶段,用户通过将上一阶段混合数据集作为其输入来使用服务器提供的预测服务。服务器和用户使用已知的半可信隐私保护预测协议(例如,Cheetah、CrypTFlow2 等)共同执行安全预测计算。
(iii)模型准确率和计算正确性验证:用户在得到整个混合数据集的预测结果后,会检查模型准确率和计算正确性。特别是,模型准确率大于设定的阈值(例如,0.95)时,则通过模型准确率验证。同样,用户通过检查每个查询样本所有副本对应预测结果的一致性来验证计算正确性。如果某个查询样本的所有B个副本中存在任意不一致的结果,则认为服务器试图通过提供不正确的预测结果来欺骗用户。如果两个检查都通过了,则用户接受预测结果,否则将拒绝。
05实验评估
下图3展示了性能对比。相比于同样实现了恶意环境下安全的预测方案(2019 CCS’ LevioSA: Lightweight Secure Arithmetic Computation),我们的方案在通信开销上减少了30.9倍,在运行时间上减少了48.06倍。
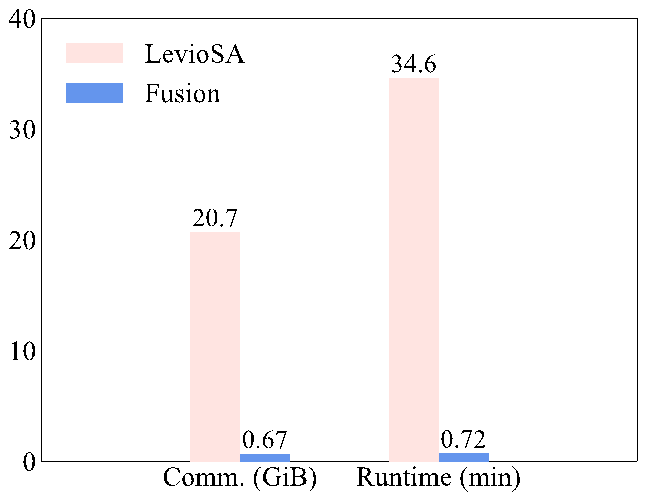
图3. 本文的方案与LevioSA的性能对比
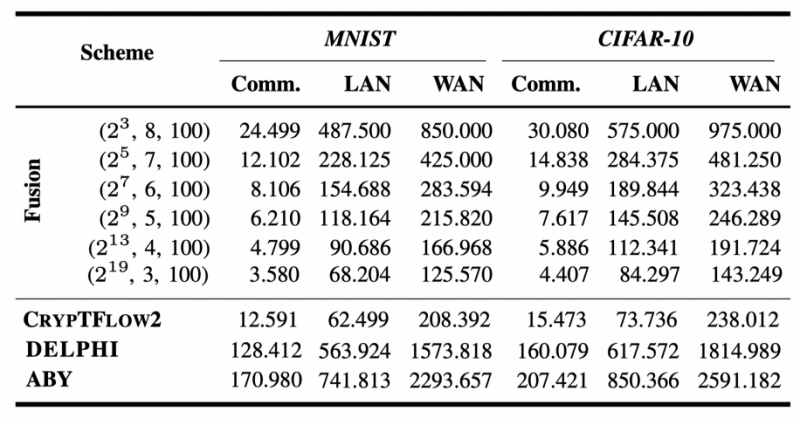
在下表1中,我们将使用Cheetah(2022 Usenix)实例化Fusion时的每个查询样本的平均时间与通信开销与半可信安全的方案CrypTFlow2(2020 CCS),DELPHI(2020 Usenix)和ABY(2015 NDSS)的通信和运行时间进行了比较。值得注意的是,Fusion 的平均成本随着 B 的降低而降低,能够实现更大的性能改进。实验结果表明,当R大于32且B小于等于7和T等于100时,Fusion在通信方面比ABY、DELPHI和CrypTFlow2更有效。例如,当使用MNIST数据集并设置R为32,B为7,T为100时,Fusion的通信成本分别比ABY,DELPHI,CrypTFlow2低14.13,10.61和1.04倍。
表1. 本方案和半可信方案的效率对比
06总结
我们提出的Fusion,它可以满足包括隐私性,模型准确率验证和计算正确性验证在内的安全需求。通过将半可信安全的预测协议(例如,Cheetah,DELPHI)转换为恶意安全的预测协议,Fusion可以用作通用编译器,可以从前沿的基于安全两方计算的预测方案中受益。我们的评估表明,与LevioSA(先进的恶意安全预测协议)相比,Fusion的速度快48.06倍,通信量减少了30.90倍。
作者简介
董彩芹,暨南大学在读博士,主要为安全多方计算及其应用,例如隐私保护机器学习和基因大数据等,曾在NDSS, IEEE TDSC等信息安全顶级会议和期刊上发表论文多篇,目前已经获得国际专利4项。担任IoT-J等多个学术期刊和会议的审稿人。




