



2022年5月,由网络安全研究国际学术论坛(InForSec)汇编的《网络安全国际学术研究进展》一书正式出版。全书立足网络空间安全理论与实践前沿,主要介绍网络和系统安全领域华人学者在国际学术领域优秀的研究成果,内容覆盖创新研究方法及伦理问题、软件与系统安全、基于模糊测试的漏洞挖掘、网络安全和物联网安全等方向。全书汇总并邀请了近40篇近两年在网络安全国际顶级学术议上发表的论文(一作为华人),联系近百位作者对研究的内容及成果进行综述性的介绍。从即日起,我们将陆续分享《网络安全国际学术研究进展》的精彩内容。
本文根据论文原文“GreyOne:Data Flow Sensitive Fuzzing.”整理撰写,原文发表于USENIX Security 2020。本文较原文有所删减,详细内容可参考原文。
01 介绍
为了使模糊测试具备处理程序复杂约束的能力,前人提出了多个相关缓解方案,例如利用符号执行技术辅助模糊测试求解这些复杂度高的约束,代表性工作有Driller、QSYM和DigFuzz,这一类工作通过采用符号执行对相应路径上的所有约束条件集合进行求解,但容易在一些类似单向函数的复杂约束或者复杂循环结构上求解失效。也有工作利用学习的方式去定位重要输入字节或者重要的变异操作,但这种方法很难精准定位和处理复杂的程序结构。相反,数据流分析技术(污点分析)被证实能更有效地指导模糊测试覆盖这些复杂约束,例如TaintScope利用动态污点分析技术定位校验和检查分支,有效地辅助模糊测试绕过校验和检查分支;VUzzer采用动态污点分析追踪MAGIC比较分支中的常量字节,可以定位其输入偏移位置,能指导模糊测试快速地覆盖这些MAGIC比较分支。Angora利用动态分析获取每个分支的污点数据,并在这些污点数据上进行变量类型推断和梯度计算。这些工作通过借助传统动态污点分析技术去指导模糊测试定位变异位置和如何变异,并且取得了一定进展。
然而,传统动态污点分析技术具有如下众多限制。
■ 针对不同的硬件平台,其指令语义具有巨大的差异,需要分别耗费大量的人力成本为各种指令类型构建污点传播规则,依赖动态污点分析技术的方法很难跨平台使用,例如VUzzer只能应用于x86平台。另外,在分析过程中,需要利用预定义好的污点传播规则对指令进行逐条解析传播分析,遇到XOR或者AND操作指令时,容易造成过污染现象。另外,针对程序中那些依赖污点数据的外部库和系统调用,也需要耗费大量人力为这些函数构建相应的污点传播模型,一旦出现未建模的外部库和系统调用指令,就会出现污点传播中断现象,从而引发严重的欠污染现象。
■ 程序中会出现严重的隐式控制流,即某个变量的数值变化只依赖分支条件,单条指令级的污点传播规则无法描述这类现象,会不可避免地引发严重的欠污染现象。也有相关工作采用额外的过程间分析技术定位隐式控制流并构建污点传播规则,但会引发严重的过污染。
■ 传统动态污点分析速度极慢,比正常执行慢数十倍以上,使其在模糊测试过程中应用严重受限。因此,引出本文中第一个研究目标:设计更轻量级和更精确的污点分析方法以适应高效的模糊测试过程。
有了精准的污点数据后,需要进一步研究如何去构建高效的种子变异策略。在过去的工作中,通过传统动态污点分析技术获取相应的污点信息后,VUzzer直接用静态分析获取MAGIC字节去覆盖相应分支对应的输入偏移。而REDQUEEN进一步识别了那些直接复制输入值的约束变量,而且这些变量经常用于MAGIC比较分支与校验和检查分支。这些工作无法识别间接复制输入值的分支约束,也不能对分支和字节的重要性进行排序,这都是影响模糊测试快速达到理想代码覆盖率的关键因素。因此,引出本文中第二个研究目标:利用精确污点数据去指导实施高效的模糊测试过程。
目前带进化能力的模糊测试方法专注于提升代码覆盖率,例如AFL一旦发现覆盖新边的种子,就立刻加入种子队列,以备后续测试使用。VUzzer、CollAFL-br通过优化种子选择策略来加速进化过程,然而,这些方法仅考虑控制流特征,缺乏精确的程序数据流特征(污点敏感的约束的一致性分析),无法满足那些复杂度高的约束条件,因此,引出本文的第三个研究目标:利用有价值的数据流特征加速模糊测试的进化过程。
针对以上研究目标,本文构建了一套基于数据流敏感的模糊测试分析解决方案GreyOne。首先提出了模糊测试驱动的污点推理方法FTI,该方法在模糊测试阶段构建一个轻量级的污点推理过程,通过对种子进行字节级的变异,结合模糊测试的方式去追踪关键约束变量的数据变化能获取更精准的污点信息。在此基础上,进一步提出了全新的字节优先级排序模型来探索重要的分支、变异字节,以及如何去变异。最后,设计了轻量级的数据流特征来描述约束的可满足性,即污染变量到未覆盖分支条件可满足的预期值的距离,这能高效加速模糊测试的代码覆盖过程。
02 数据流敏感的模糊测试系统GreyOne设计
GreyOne架构设计如图1所示,GreyOne的总体工作流程和AFL相似,主要分为种子生成、种子选择、种子变异、测试和状态追踪等步骤。
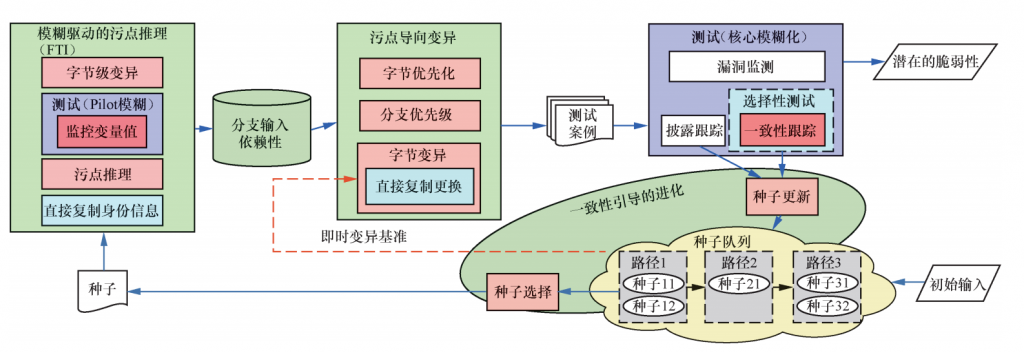
图1
首先,GreyOne在模糊测试流程中引入了FTI环节,用来推理变量的污点信息和各分支的属性。在该环节中,通过对输入种子进行字节级的变异和测试,并且对所覆盖路径的分支变量进行监测,一旦发现变量值产生变化,就把该变异字节推断为该变量的污点数据。另外,该环节还会识别被污染的变量是否直接复制了种子输入(对应研究目标一)。
其次,通过FTI获取了污点数据后,GreyOne会进一步构建高效的变异策略,包括对种子的污点字节和未覆盖分支进行优先排序,另外针对未覆盖分支的属性(直接复制输入值和间接使用输入值),采用相应的变异策略(对应研究目标二)。
最后,设计约束一致性制导的进化模型加速代码覆盖过程,该模型不仅追踪路径覆盖情况,还需要追踪污染分支对应的约束一致性,并且把更高的约束一致性的种子加入种子队列,这样可以在后续的测试中逐步地提升该约束的一致性,从而逼近相应的未覆盖分支。另外,该模型设计了基于一致性的种子选择策略,加速进化过程。在变异的过程中,一旦产生一致性更高但不发生路径改变的种子,会即时更新当前种子,在下一步变异中立即把更高一致性的种子作为变异对象,这样进一步提升了变异效率(对应研究目标三)。
1. FTI:模糊测试驱动的污点推理方法
传统动态污点分析能够帮助模糊测试提升变异效率,提升代码覆盖。然而,传统方式需要耗费大量的人力,运行速度慢,并且存在大量的过污染和欠污染现象,GreyOne引入一种轻量级和精准的解决方案,即模糊测试驱动的污点推理方法FTI。FTI采用最直观的推断方式,即对种子中某个字节变异后进行测试,如果发现种子的路径上的分支变量值发生变化,那么受影响的变量数据依赖于该变异字节。
和传统污点分析相比,FTI只需很少的人工干预,并且大幅提升了速度性能和精确性,具体如下。
■ 工作量。传统污点分析需要对每种指令手写污点传播规则,而且难以同时适应不同平台,对于和输入相关的所有外部库,都需要重写引入污点分析机制。相比之下,FTI可以避免以上所有的问题。
■ 速度。FTI通过静态插桩监测相应的变量,不像传统污点分析需要对每条指令都进行监测和解析,因此,FTI能适应更复杂程序。
■ 精确性。传统污点分析会面临严重的过污染和欠污染新现象,而FTI不会出现过污染现象。事实上,FTI还能避免隐式控制流或者为建模外部库引入的欠污染现象,但是字节级的变异也有可能因为变异不充分引发特定的欠污染,在这方面FTI也会引入相应的处理方案。
2.污点制导的变异策略
GreyOne会利用FTI推理得到污点数据去构建变异策略,首先对输入的字节进行排序,根据字节排序情况再对未覆盖分支进行排序,最后按次序选择分支进行变异。
(1) 字节排序。文献指出,种子中的不同字节对覆盖率的影响具有差异性,可以通过优先变异一些字节,帮助模糊测试更容易达到理想的代码覆盖,该工作把种子字节分为对覆盖率有用和无用两类,但对于有用的字节不再进一步区分。基于此,GreyOne提出:如果一个字节影响的未覆盖分支越多,那么该字节应该被优先选择变异。可以直观地理解为,如果对一个影响更多未覆盖分支约束的字节进行变异,那么覆盖新边和新行为的可能性越大。
种子输入字节(seed input bytes)、变量(program variables)、分支(branches)之间依赖传播关系。输入种子的每个字节可能影响多个变量,从而影响多个未覆盖分支,如图2所示。
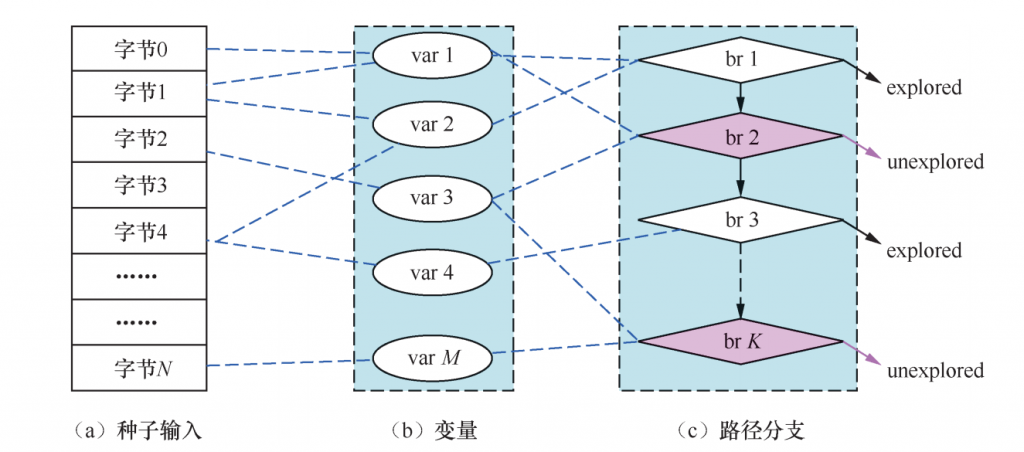
图2
本文给FTI推理得到污点字节定义的权值计算方法如下:

其中,IsUntouched函数表示分支br是否被覆盖,如果未覆盖,返回1,否则返回0。DepOn函数表示分支br是否依赖于第pos个输入字节,如果依赖,返回1,否则返回0。
分支排序。在图2中,程序中一条路径可能包含多个未覆盖分支,从变异的角度考虑,如果一个未覆盖分支br受依赖的输入字节影响的未覆盖分支越多,那么变异该分支br也会影响越多的未覆盖分支的状态,从而产生更高的代码覆盖,因此,GreyOne为未覆盖分支定义了以下排序规则,对于任意种子S,未覆盖分支br的权重计算方法如下:
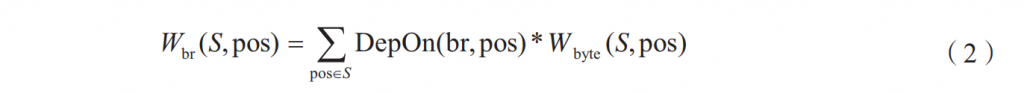
3.一致性制导的进化模型
不同于其他的模糊测试工具,GreyOne利用数据流特征构建进化模型,专门用来处理高复杂度的间接使用输入的分支。需要特别注意,对于未覆盖分支中的污点变量,通过对它的依赖输入字节进行翻转操作,如果当前变异操作使得污点变量的相关约束两侧变量的距离越来越近,那么在新的约束条件下进行变异操作,更容易满足当前约束。
根据以上观察,GreyOne提出利用种子的约束一致性控制模糊测试的进化方向,在变异的过程中,实时评估种子的约束一致性,可以识别有效的变异结果,不断地把约束一致性高的种子更新到队列中,而且结合种子选择策略,不断优先选择约束一致性高的种子进行变异,可以大幅加速代码覆盖过程。
(1) 一致性计算。约束一致性的评估为了展示输入种子对当前约束的满足程度,而一条路径包含多个基本块和分支约束,因此,为了评估整个测试例的一致性时,需要先计算分支或基本块的一致性。
■ 未覆盖分支的一致性评估。由于GreyOne计算测试例的一致性是为了评估该测试例产生新代码的能力,因此,在考虑分支一致性时候,可以过滤掉已经覆盖的分支,只计算未覆盖分支的一致性,具体如下:
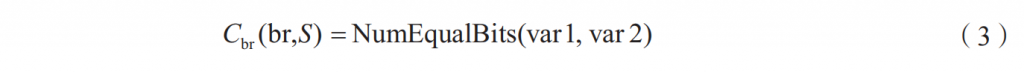
其中,函数NumEqualBits返回参数var1和var2相同的bit位的数量,需要特别注意,对于switch分支,该参数会依赖switch多个case值。
■ 基本块的一致性评估。对于种子S和所跑的基本块bb,bb可能有个未覆盖邻近边(switch指令),GreyOne会把bb的约束一致性计算为:
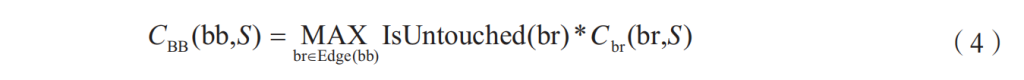
即把未覆盖邻近边里一致性最高的看作当前基本块的一致性。
■ 测试例的一致性评估。对于所给的测试例S,其约束一致性可以定义为所跑路径上所有基本块的一致性的累加和:
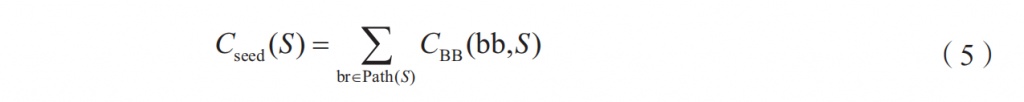
该定义表示,一个约束一致性更高的种子可能包括以下特征:具有更多的未覆盖邻近边;单个未覆盖分支的约束一致性可能更高。
(2) 一致性制导的种子更新。GreyOne不仅识别覆盖新边的种子,还识别约束一致性更高的种子,需要构建特定的种子队列进行存储和管理。传统的种子队列采取一维链表的存储方式,主要关注路径差异,每个节点存储一条唯一的路径,而GreyOne把每个节点扩展为存储多个种子,这些种子跑相同的路径但具有不同的基本块一致性分布,形成一个二维的种子队列,图3展示了GreyOne的种子更新过程,主要包括3种情况:
■ 一旦产生覆盖新边的路径,GreyOne会将该种子直接加入队列,类似于AFL的更新操作;
■ 一旦产生重复的路径,如果该路径的一致性高于队列中相同路径的一致性,就替换队列中一致性低的路径对应的节点;
■ 一旦产生重复的路径,且该路径的一致性和队列相关路径的一致性相等,并且在基本块的一致性分布上不一致时,就直接把种子添加到队列中存储该路径的节点中。
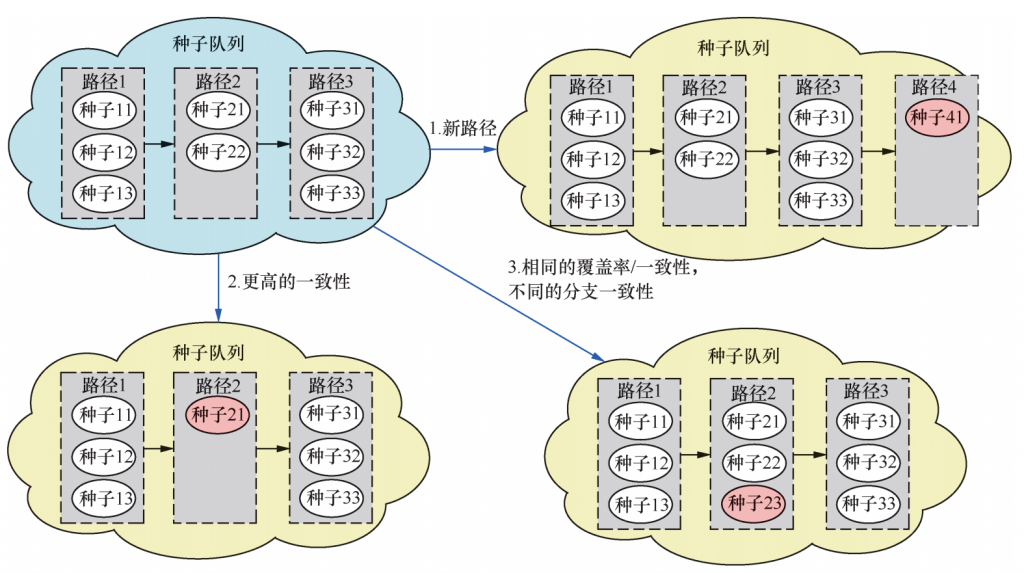
图3
(3) On-the-fly变异过程。值得注意,GreyOne在对当前种子进行变异时,一旦产生跑相同路径但一致性更高的新种子时,不仅把新种子更新到二维队列中,而且会立刻用新种子替换当前种子,这样新种子在后续的变异操作中立刻得到使用,这一操作能有效加快进化过程,可以让LAVA-M测试集产生相同bug的时间缩短到原来的1/3。
(4) 一致性制导的种子选择。种子选择策略可以加速进化过程,GreyOne根据上述公式计算出的权值对队列不同路径进行排序,会大概率地选择权重高的路径,在路径节点上,随机地选择节点上不同的种子,这样可以不断选择利于不同未覆盖分支的种子。
(本文选取了文章部分章节,更多精彩内容请阅读《网络安全国际学术研究进展》一书。)
作者简介
甘水滔,数学工程与先进计算国家重点实验室副研究员,清华大学网络研究院博士后。他的研究方向主要为系统安全,他长期研究各类程序分析技术和漏洞智能化挖掘技术。他过去主持各类课题10余项,获得省部级科技成果奖3次,发表论文20余篇,包括以一作身份发表研究成果于IEEE S&P、USENIX Security、IEEE TDSC等网络安全顶级会议和期刊上,构建了CollAFL、CollAFL-bin、GreyOne等高效漏洞挖掘系统。他在多种主流应用程序、内核程序上挖掘大量漏洞,获得CVE编号超过160个。
版权声明:本书由网络安全研究国际学术论坛(InForSec)汇编,人民邮电出版社出版,版权属于双方共有,并受法律保护。转载、摘编或利用其它方式使用本研究报告文字或者观点的,应注明来源。




