



编者按
2022年5月,由网络安全研究国际学术论坛(InForSec)汇编的《网络安全国际学术研究进展》一书正式出版。全书立足网络空间安全理论与实践前沿,主要介绍网络和系统安全领域华人学者在国际学术领域优秀的研究成果,内容覆盖创新研究方法及伦理问题、软件与系统安全、基于模糊测试的漏洞挖掘、网络安全和物联网安全等方向。全书汇总并邀请了近40篇近两年在网络安全国际顶级学术议上发表的论文(一作为华人),联系近百位作者对研究的内容及成果进行综述性的介绍。从即日起,我们将陆续分享《网络安全国际学术研究进展》的精彩内容。
本文根据论文原文“Not All Coverage Measurements Are Equal: Fuzzing by Coverage Accounting for Input Prioritization”整理撰写,原文发表于NDSS 2020,作者为王衍豪、贾相堃、刘昱玮、Kyle Zeng、Tiffany Bao、Dinghao Wu、苏璞睿。本文较原文有所删减,详细内容可参考原文。
一、介绍
模糊测试已经被广泛地用于寻找真实世界的软件漏洞。谷歌和苹果等公司都部署模糊工具来发现漏洞。研究人员针对模糊技术提出了各种改进。特别是,覆盖率指导的模糊测试近年来已经得到很多研究。与一般的模糊测试根据给定的格式规范生成输入(种子)不同,覆盖率指导的模糊测试不需要输入格式或程序规范等知识。相反,覆盖率指导的模糊测试会随机地改变输入并使用覆盖率指导输入的选择和变异。
AFL利用边覆盖率(又称分支覆盖率或转换覆盖率),libFuzzer支持边和基本块两种覆盖率。具体来说,AFL保存下所有能带来新边的输入(种子),并按文件大小和执行时间的乘积作为分数对输入进行优先级排序,同时确保优先级高的种子能够覆盖所有已经发现的边。基于AFL,最近的工作为边覆盖率添加了更细粒度的信息(如调用上下文、内存访问地址或连续的基本块等)。
然而,以前的工作平等对待不同的边,忽略了边的目的路径中存在漏洞的可能性不同的事实。因此,对于所有能够带来新覆盖率的输入,即使它触发漏洞的可能性很低,仍被视为与其他的输入同等价值进行变异和测试。虽然这样的设计对于程序测试是合理的(因为测试的目标是全面覆盖),但推迟了漏洞的发现。
VUzzer通过降低错误分支的优先级的方法来缓解上述问题,但因为依赖污点分析而成本高昂。CollAFL提出了另一个优先级算法来指导模糊测试过程,但它不能保证优先级高的种子覆盖所有的安全敏感路径,从而可能导致模糊测试困在部分无用代码中。AFL-Sensitive和Angora添加了更多辅助指标到边覆盖率,但是不同的边仍然被同等地考虑。LEOPARD考虑了函数覆盖率而不只是边覆盖率,它根据函数复杂度计算不同权重,但该方法需要静态分析来进行预处理,会导致额外的性能开销。更糟糕的是,这些方法都会受到模糊测试对抗技术(Anti-Fuzzing)的影响。因此,我们需要一种能够更倾向于漏洞但不受模糊测试对抗技术影响的新的种子选择方法。
在本文中,我们提出了覆盖率审计,一种新的种子选择方法。我们的基本思想是,任何尝试向边覆盖率添加附加信息的方法都无法战胜模糊测试对抗技术,因为无法战胜的根本问题在于当前的边覆盖率指导的模糊测试对不同边不加区别。此外,内存破坏漏洞和敏感内存操作密切相关,这些敏感内存操作可以从不同的粒度表示,如函数级、代码结构级和基本块级。为了有效地发现内存破坏漏洞,我们应该只关注和安全敏感操作相关的边。基于这样的观察,我们的方法从函数级、代码结构级和基本块级对边进行评估,并将边标记为不同级别的3个指标。我们通过新的安全敏感的覆盖率,调整种子的优先级,即按安全敏感的边的命中计数对种子进行优先级排序,同时确保所选种子能够覆盖所有访问过的安全敏感的边。
基于上述方法,我们开发了TortoiseFuzz,一种灰盒覆盖率指导的模糊测试工具。TortoiseFuzz不依赖污点分析或者符号执行,唯一的改动是向AFL的队列剔除步骤中插入的覆盖率审计。
TortoiseFuzz虽然很简单,但在发现漏洞方面却很强大。我们利用30个流行的真实程序构建了实验测试集,与4个先进的灰盒模糊测试工具和2个混合模糊测试工具进行了对比。我们计算了发现的漏洞数量,并计算了曼-惠特尼U检验来证明结果的统计显著性。
TortoiseFuzz 的表现明显优于 6 个模糊测试工具中的 5 个(AFL、AFLFast、FairFuzz、MOPT 和 Angora)。TortoiseFuzz 的漏洞发现能力和 QSYM 相当,但平均只消耗了约 2% 的 QSYM 内存资源。TortoiseFuzz 共发现了 20 个 0day 漏洞,其中 15 个得到了 CVE 确认。我们还将覆盖率审计与 AFL-Sensitive 和 LEOPARD 进行了对比,实验表明我们的指标在发现漏洞方面比其他两个指标更好。此外,我们将覆盖率审计应用于 QSYM,使 QSYM 的漏洞发现能力平均提高了 28.6%。
我们在 GitHub 上开源了 TortoiseFuzz 的源码。
02
二、背景
1.覆盖率指导的模糊测试
模糊测试是一种通过不断生成和测试输入来寻找软件漏洞的程序自动化测试技术。它可以灵活地应用于不同的程序,不需要了解程序,也不需要手动生成测试用例。具体来讲,覆盖率指导的模糊测试以一个初始种子和目标程序作为输入,生成能够触发程序错误的种子,整个测试过程构成一个循环。在循环中,它重复选择种子,以种子为输入运行目标程序,并基于当前种子和运行结果生成新的种子。覆盖率用作选择种子的度量标准。
图1展示了覆盖率指导的模糊测试工具AFL的架构。AFL首先读入所有的初始种子并保存在队列中(①),然后从队列中选择一个种子(②)。对于每个种子,它通过不同的策略进行变异(③),并把生成的新样本发送到一个Fork出来的服务器进行测试(④)。在测试过程中,AFL用一个全局的结构收集覆盖率信息,如图1中以基本块标识符标记的边覆盖率储存在bitmap中(⑤)。如果一个目标程序发生崩溃,那么就生成一个报告,其中能够使程序发生崩溃的种子就是这个漏洞的PoC(⑥)。如果生成的新样本能够引起覆盖率变化,那么该样本就作为“有趣的”种子保留到种子队列(⑦)。
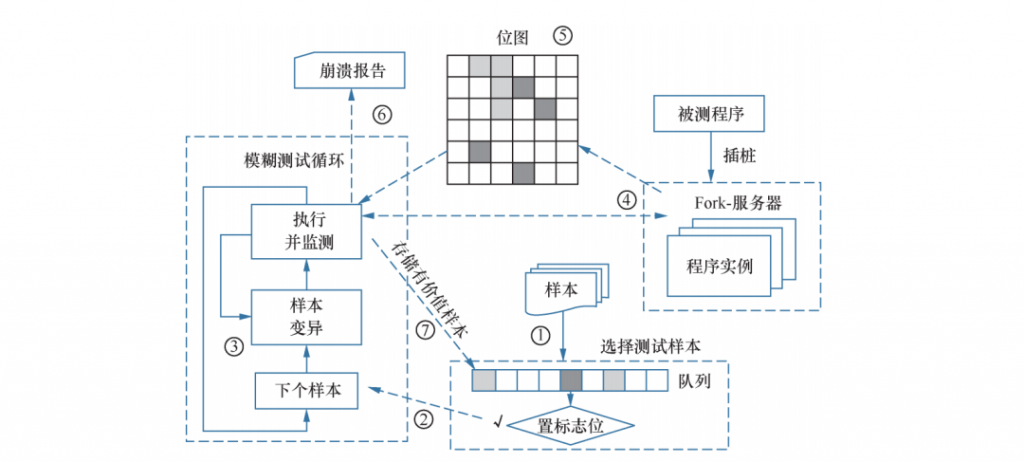
图1
2.种子优先
种子优先是为未来的种子变异和选择服务的。覆盖率指导的模糊测试利用覆盖率信息计算优先级。不同的模糊工具采用不同的覆盖率标准,如基本块覆盖率、边覆盖率和路径覆盖率。与基本块覆盖率相比,边覆盖率更加精细敏感,因为它考虑到了基本块转移的方向,同时它比路径覆盖率更具可扩展性,避免了路径爆炸。
AFL及其子代使用边覆盖率来计算种子的优先级。具体是由两部分计算得到的:输入过滤(图1中的步骤⑦)和队列剔除(图1中的步骤①)。输入过滤就是过滤掉不“有趣”的输入,即没有引起覆盖率或命中次数变化的种子。队列剔除是对种子队列进行排序,它并不会丢弃种子,但重新组织了队列中的种子。优先级低的种子之后获得更少的测试机会。输入过滤发生在每次种子执行之后,队列剔除则是在一定数量的种子执行之后,由变异能量调整策略控制。
(1) 输入过滤。在模糊测试过程中,AFL会保留以下两种情况的新种子:一是新种子触发了新的边,二是新种子触发了已经发现的边的更多的次数。因此,AFL设计了记录边覆盖率的结构,通过给不同的基本块分配不同的ID,按照图2中的公式记录基本块之间的边信息,记录到bitmap。其中cur_location是指当前基本块,prev_location表示前一个基本块(会根据当前基本块更新,如公式第三行),两者异或的值作为bitmap的index。

图2
对于每一条边,AFL记录边是否被执行过,并记录边的访问次数,通过分桶的方式对访问次数进行处理。当访问次数发生比较大的变化时,会记录下该种子。另外,因为边覆盖率被记录在bitmap结构上,在记录过程中可能遭遇哈希碰撞问题,CollAFL指出并缓解了该问题。
(2) 队列剔除。队列剔除的目的是在保留已经发现的覆盖率的前提下尽量简化种子队列。由于保留的种子能够覆盖的代码可能存在重叠的情况,因此AFL在保证覆盖率的情况下,会选择一个种子队列子集优先测试。具体来讲,AFL倾向于更小的种子文件和更短的执行时间。因此,它首先标记所有没有被覆盖的边,然后循环地标记能够包含未覆盖边的种子,并选择文件大小和执行时间乘积更小的种子进入最终的子集,并把该种子能覆盖的其他边标记为已覆盖。循环上述过程直到没有种子或所有的边已经被覆盖。
在AFL的实现中,发现每条边的最佳种子(即种子的文件大小和执行时间的乘积更小)发生在输入过滤阶段,而不是队列剔除阶段。具体来讲,AFL维护了一个top-rate结构,以边为键、以种子为值。在输入过滤过程中,如果AFL要保留该种子,它将计算该种子的文件大小和执行时间的乘积,更新top-rate结构。对于一条边,如果边对应的最佳种子的文件大小和执行时间的乘积不如新的种子,那么就会发生替换操作。通过这种方式,AFL能够相对简单地按照倾向性保留更有价值的种子。
(3) 种子优先的改进。尽管边覆盖率在代码覆盖率和路径覆盖率之间有很好的平衡,但是对于输入优先还是不够的,因为它没有考虑更细粒度的上下文。因此,有一些工作尝试在原有的覆盖率上增加更多的信息。Angora增加了调用栈信息,AFL-Sensitive增加了如内存操作地址、基本块的N-gram信息等。
这些改进使得代码覆盖率更细粒度,然而仍然无法避免在模糊测试过程中陷入无用代码中。例如进入错误处理代码虽然能够增加代码覆盖率,但对于发现漏洞意义不大。VUzzer通过降低优先级的方法处理上述问题,但是它需要额外的重量级分析识别错误处理代码,影响模糊测试的高效性。CollAFL提出了一个新的覆盖率指标,以整个执行过程中的内存操作数量为指导。然而CollAFL无法保证被优先的种子能够覆盖所有已经访问过的边。因此它会很容易陷入一个充满了内存操作但并没有危险的代码片段中,如字符串赋值函数。LEOPARD在进行队列剔除的同时,根据一个函数级复杂度进行了额外计算,这样能够保证保留下所有的已经覆盖的边的信息,然而VUzzer一样需要提前对程序进行分析,带来了额外的开销。
3.种子变异和能量分配
通常,种子变异也可以看作是种子优先的算法延续:如果我们把输入空间看作所有字节的组合,那么种子变异通是对输入空间中的子集进行优先级排序。以往的工作设计了综合变异策略和变异调度方法。这些方法可以作为我们种子优先方案的补充。
同样地,能量分配是通过调节后代种子变异来实现种子优先的,如AFLFast、AFLGo、FairFuzz等。AFLFast基于马尔可夫模型对低频种子进行能量调节,AFLGo则直接对目标代码赋予更高的能量。FairFuzz是标记了命中次数少的分支,并向该部分分支分配更多的测试能量。
4.模糊测试对抗
目前的模糊测试对抗技术主要通过覆盖率指导的两个设计缺陷使模糊测试工具失效:一是大多数模糊测试工具没有区分覆盖的不同边,二是混合模糊测试使用重量级的污点分析或符号执行技术。模糊测试对抗技术通过插入伪造路径、在错误处理代码中添加延迟、或者混淆代码来降低动态分析的速度来阻碍模糊测试。
目前的模糊测试对抗技术可以造成高达85%的路径探索能力下降。不幸的是,很多边覆盖率指导的模糊测试工具都无法处理对抗技术。VUzzer因为用到污点分析而受到严重影响,LEOPARD在考虑函数级复杂度的时候,受到伪造分支的严重影响。AFL系列的模糊测试工具同样受到伪造分支的影响,增加额外信息的方法由于不区分覆盖的边而无法解决对抗问题。
(本文选取了文章部分章节,更多精彩内容请阅读《网络安全国际学术研究进展》一书。)
作者简介
王衍豪,博士,蔚来汽车信息安全专家。他的主要研究领域为程序脆弱性分析、嵌入式设备安全、APT检测。
贾相堃,博士,中国科学院软件研究所副研究员。他的主要研究领域为系统安全、程序分析、漏洞挖掘与分析。
刘昱玮,中国科学院软件研究所在读博士研究生。他的主要研究领域为漏洞挖掘、分析和利用。
版权声明:本书由网络安全研究国际学术论坛(InForSec)汇编,人民邮电出版社出版,版权属于双方共有,并受法律保护。转载、摘编或利用其它方式使用本研究报告文字或者观点的,应注明来源。




