



论文题目:MOPT:Optimized Mutation Scheduling for Fuzzers(本文选自USENIX Security 2019)
论文作者:Chenyang Lyu,Shouling Ji,Chao Zhang,Yuwei Li,Wei-Han Lee, Yu Song, Raheem Beyah
作者单位:Zhejiang University, Alibaba-Zhejiang University Joint Research Institute of Frontier Technologies, BNRist & INSC, Tsinghua University, IBM Research, Georgia Institute of Technology
论文地址:https://www.usenix.org/system/files/sec19-lyu.pdf
论文代码:https://github.com/puppet-meteor/MOpt-AFL
1.背景介绍
模糊测试是最高效的漏洞挖掘技术之一,大体工作流程如下。
模糊测试工具会维护一个seed pool,每次工具从seed pool中选出一个种子文件,对它进行Rt次变异过程。在每次变异过程中,工具选用Ro个变异操作对种子文件进行修改,最终得到Rt个测试用例。然后工具使用Rt个测试用例去测试目标程序,如果用例触发了程序的异常行为,就认为该用例为interesting test case,并将该用例保存到seed pool中,作为后续变异的种子文件。如果用例触发了新的执行路径,许多工具也会认为这一用例是interesting test case并保存到本地seed pool中。
许多文章致力于开发更高效的模糊测试工具,如CCS 2016的AFL-Fast和NDSS 2017的VUzzer着力于提高模糊测试的执行路径覆盖率并探索较少受到测试的低频执行路径。
现存的工具大多使用均一分布作为变异操作的调度策略,由于工具通过选择变异操作来生成触发异常行为的测试用例,那么,使用均一分布来选择变异操作是否为合理的调度策略呢?
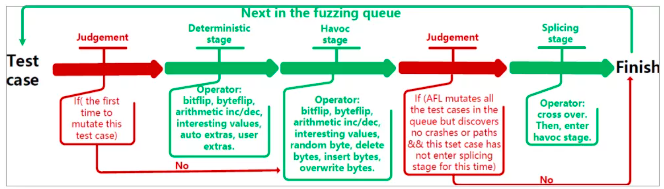
以模糊测试工具AFL为例,它实现了11类不同的变异操作,其中16个操作使用频率最高。如图是AFL的变异调度过程,第一次进行变异的种子文件首先要进入deterministic stage,在这一阶段每个变异操作会对种子文件的每个byte或者bit进行变异,以此生成庞大数量的测试用例来测试目标程序。在结束了deterministic stage后,进入havoc stage,AFL从变异操作中随机选Ro个对种子文件进行变异,并使用变异后的测试用例来测试程序。第三个阶段是splicing stage,进入这一阶段的判断条件很苛刻,如果AFL变异了seed pool中的所有种子文件,得到的测试用例仍然没有发现新的interesting test cases,AFL才会执行这一阶段,splicing stage只执行一个变异操作:随机选取另一个种子文件,将它和当前文件的部分内容拼接在一起,然后重新进入havoc stage进行变异。
分析得出deterministic stage和havoc stage使用的最多,splicing stage由于判断条件很少用到。而且,AFL在havoc stage中使用均一分布选择变异操作。但不同变异操作发现interesting test cases的效率是一样的吗?
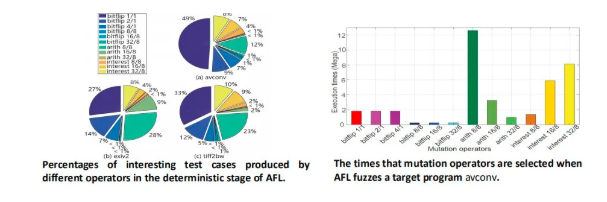
我们进行实验来求证这一问题。左图为12个变异操作发现interesting test cases的比例,在同一目标程序上,不同的变异操作发现interesting test cases的占比不同。而且,同一个变异操作在不同目标程序上的占比也不同。
右图为AFL在测试avconv时每个变异操作的执行次数。可知,产生了许多interesting test cases的bitflip执行次数较少,后面较为低效的操作执行次数却较多。故AFL花费了大量时间来执行低效的变异操作。
其次,我们探究AFL在三个阶段花费的时间以及发现的interesting test cases占比。可以观察到,splicing stage几乎没有占用时间,多数情况下,deterministic stage占用了大量时间,发现的却没有占到相应的比例。所以,AFL投入了大量的时间在deterministic stage,但回报不值得。
综上,不同变异操作在同一测试程序上挖掘interesting test cases的效果不同,同一操作在不同程序上的效果不同。AFL花费了许多时间在低效的变异操作,且花费大量时间在deterministic stage。
显然,工具应该花费更多的时间来执行高效的变异操作,需要一个更好的调度策略。
2.调度策略MOPT
首先确认实现MOPT的stage阶段。由于deterministic stage的变异是固定的,而splicing stage只有一个变异操作,占时极短,故我们实现MOPT的阶段是havoc stage。基于粒子群算法,设计了如下调度策略。MOPT有复数个粒子群,每个粒子群中有着跟变异操作相同个数的粒子,每个粒子所在位置Xnow为对应变异操作的选择概率。粒子根据粒子群算法在概率空间中游走,并整合成所有变异操作的选择概率分布。所以每个粒子群是一个选择概率分布,故MOPT有复数个概率分布。
MOPT的具体框架如图,大体分为四个模块。
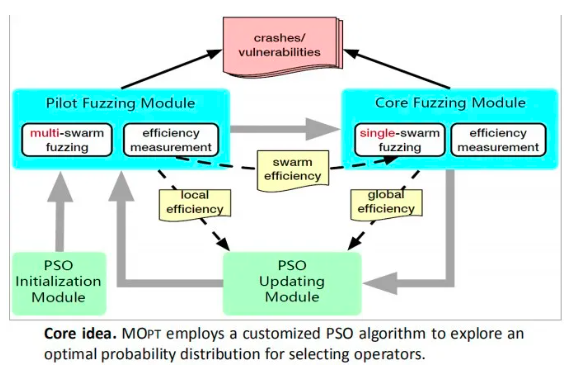
首先是PSO initialization module,为所有粒子群赋予初值,只在模糊测试过程开始的时候执行。
随后是pilot fuzzing module,在这一模块中,MOPT将测试每一个粒子群的概率分布。MOPT将使用一个概率分布生成固定个数的测试用例来测试程序,探究这些概率分布的效率。在每一概率分布的作用下,MOPT会记录每个粒子对应的变异操作发现interesting test cases的次数和执行的次数,这两个数值用以求解该粒子的local best。并且记录该粒子群本次迭代过程中发现的interesting test cases的数量,用以求解本次迭代中该粒子群的效率。
当每个粒子群都完成上述操作之后,pilot fuzzing module结束,MOPT进入core fuzzing module。MOPT根据本次迭代中每个粒子群的interesting test cases挖掘效率,选用效率最高的粒子群的概率分布进行漏洞挖掘,并执行固定次数后结束。此时MOPT统计每个变异操作的执行总次数与发现的interesting test cases的总个数,用以求得global best。
在结束core fuzzing module后,MOPT进入PSO updating module,并根据global best和每个粒子的local best值,对每个粒子的位置(即对应变异操作的选择概率)Xnow进行更新,随后对每个粒子群的粒子位置归一化,得到总和为1.0的概率分布。最后进入pilot fuzzing module执行下一轮迭代。
由于AFL在deterministic stage花费的时间极多,但实现的MOPT位于havoc stage,显然deterministic stage会影响MOPT的迭代速率,进而影响MOPT的效果。于是我们设计了pacemaker fuzzing mode:如果AFL在长时间To中没有发现新的interesting test cases,MOPT就会在后续变异中跳过deterministic stage,只执行havoc和splicing stage。我们设计了两种,一种是禁止deterministic stage后不再启用的-ever版本,一种是发现了足够数量的interesting test cases时,会重新启用deterministic stage的-tmp版本。
3.实验与分析
进入evaluation部分,首先介绍的是测试对象,我们从以往论文中选取了通常使用的一些目标程序作为测试对象。
实验结果如图所示,MOPT-AFL-tmp和-ever发现的crash数量为AFL的四倍,两者也发现了比AFL多一倍的程序路径。
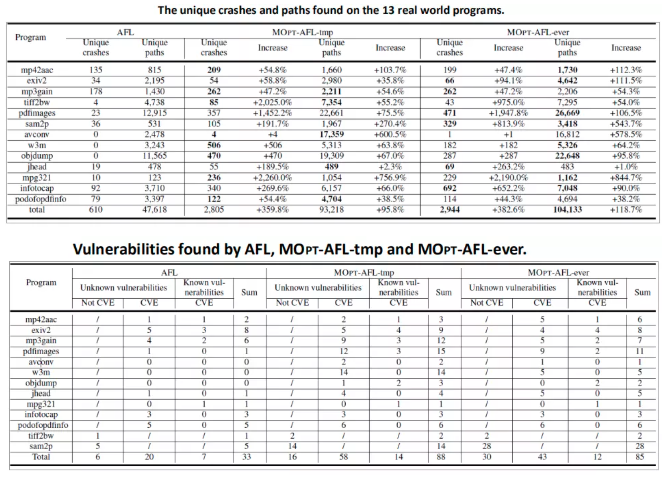
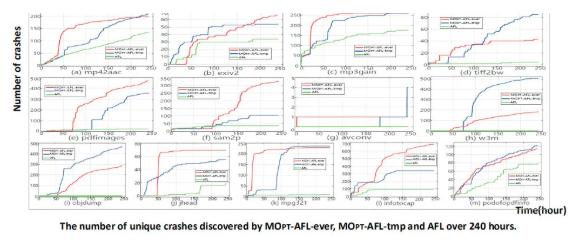
随后我们使用address sanitizer对crash筛选,得到unique bugs,对比已公开的CVE,将未发现的bugs提交给厂商并申请CVE,最后总结得到上表内容。其中,AFL发现了20个新的CVE和7个已公开的CVE。而MOPT-AFL-tmp发现了58个新的CVE和14个已公开的CVE。MOPT-AFL-ever发现的CVE总数也达到了AFL的两倍。所以,MOPT-AFL的漏洞挖掘效率很高。
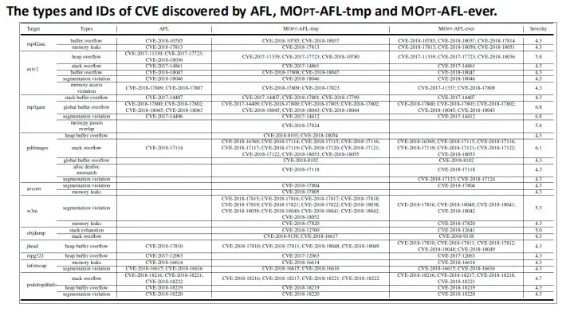
在实验过程中我们记录了3个fuzzers的crash个数与时间的关系,可以看到MOPT-AFL发现crash的速率显著快于AFL。
现存fuzzers使用均一分布来选择变异操作,于是我们在AFL-Fast和VUzzer上实现了MOPT调度策略来测试兼容性。由实验结果可知,MOPT可以提高AFL-Fast和VUzzer的漏洞挖掘表现。
随后我们在LAVA-M数据集上测试了10种fuzzers组合,并发现了一些有趣的结果。首先MOPT可以提高fuzzers的表现;其次在与Angora和QSYM的实验中,MOPT显著提高了漏洞个数,说明MOPT和符号执行技术(或近似的技术)是互补的,一同使用可以发现最多数量的漏洞。
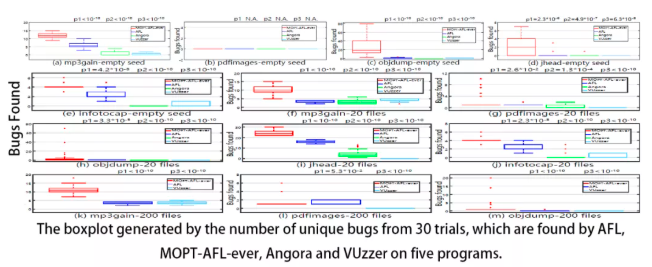
后续进行统计学性质的实验。我们选取MOPT-AFL-ever,AFL,Anogra和VUzzer在五个目标程序上进行测试(分别使用三种不同的初始种子集),每次测试持续240小时,重复30次,评价标准是发现的crash和bug的数量,并且用p value分析两个fuzzers的表现是否有显著差别,p值很小说明存在显著差别,反之无显著差别。
首先是crash的统计分析结果,可以看到大部分测试用例中,MOPT-AFL-ever显著多于其它fuzzers。从箱型图看出,很多实验中MOPT-AFL-ever的最小值都大于其它fuzzers。
随后是bug的统计分析结果,可以看出MOPT-AFL-ever发现的bug多于其它fuzzers,p value也证实两个分布是差距显著的。
分析MOPT主要框架和pacemaker fuzzing mode对漏洞挖掘的影响,实现了不使用pacemaker fuzzing mode的MOPT-AFL-off,和只实现pacemaker fuzzing mode的AFL-ever进行测试。从实验结果可以得出,两个部分都能提高AFL效率,结合在一起提高的最多。
然后分析实验中不同的mutation operators的选择概率变化。我们列出三个operators在两个目标程序上的概率迭代图。首先纵向对比,不同的operator最终具有不同的选择概率,如测试pdfimages时三个概率分别大约是6.5%,4%,7.5%。纵向对比亦证实了在不同的目标程序上,同一个operator最终收敛的概率并不相同。
对MOPT引入的计算消耗进行分析,我们使用fuzzer的执行速率来分析MOPT是否对fuzzing过程造成计算负担。结果证实,大部分案例中,MOPT几乎没有影响执行效率,部分情况下执行速率快于AFL。在mp3gain实验中,虽然MOPT-AFL比AFL的执行速率慢,但是仍发现了更多的crash和bug。
最后进行长时间的并行试验。对于每一个fuzzer工具,我们运行了三个进程并行地挖掘pdfimages的漏洞,实验持续了24天,每个fuzzer的CPU时间超过了70天。结果表示,MOPT-AFL发现的crash和path显著多于AFL。
总结,我们调查了变异调度策略存在的问题,提出MOPT并证明其有效性,MOPT-AFL源码已在github上开源。
作者简介:
吕晨阳,浙江大学直博三年级生,研究方向:漏洞挖掘,模糊测试,神经网络。




