



社交网络中的用户属性预测
作者:龚真强 (Neil Gong),爱荷华州立大学电子和计算机工程系
社交网络已经成为不可或缺的网络平台。用户用社交网络相互通信、传播信息、以及扩大社会影响力。在一个社交网络中,一个用户通常有朋友、行为数据、内容数据、以及属性数据。举例来说,行为数据可以是一个用户喜欢过的网页、电影、书或移动App。内容数据可以是一个用户写的博客、上传的照片等等。属性数据包含用户的身份、性别、年龄、性取向、政治倾向、宗教信仰等等。有些用户在社交网络中公开自己的朋友、行为、内容、以及属性数据。然而有些用户选择不公开或者不提供自己的某些数据,比如各种属性。总的来说,一个社交网络可以看作是公开数据和隐私数据的结合。
本文介绍针对社交网络用户的属性预测攻击。属性预测是社交网络用户面临的一个严重的隐私和安全攻击。在一个属性预测攻击中,攻击者首先收集社交网络中用户的公开数据,然后利用机器学习、数据挖掘方法来预测目标用户的隐私属性。攻击者可以是任何对用户属性感兴趣的个人或组织,比如社交网络供应商、广告商、黑客、数据经纪商等。社交网络供应商和广告商可以利用预测的属性来提供定向广告,从而提高盈利。黑客可以利用预测的属性来进行定向的、更有效的社交工程攻击,比如黑客如果知道一个用户毕业的学校,黑客给这个用户发送恶意网址的时候,可以将该网址描述为与该用户学校相关的信息,从而提高用户点击恶意网址的概率。数据经纪商可以将预测的属性数据卖给广告商、银行、以及保险公司等,从而获得经济利益。更为严重的是,攻击者可以利用预测的属性将用户在不同社交网络的账户关联起来,甚至将网络中的数据和线下数据关联起来,形成更全面的用户数据,从而造成更大的隐私和安全隐患。
基于写作风格的作者身份预测
有些用户在发表一些敏感的文字内容时,常常选择匿名。这些敏感的文字可能涉及政治话题,或者敏感的个人生活、健康问题。所以,准确的预测这些敏感文字的作者会对作者造成极大的伤害。在网络犯罪取证中,IP地址可以作为一个基本的定位作者的信息。然而,作者可以利用VPN,Tor等手段来回避基于IP地址的分析。
我们介绍一个基于写作风格的作者身份预测攻击[1]。该攻击的理论基础是不同作者有不同的写作风格。具体的说,两个作者在表达同一个事物时,会选择不同的字或词语,或者对同一个字的使用频率有所不同。比方说,一个用户会频繁的使用“我”,而另一个用户可能会频繁的使用“我们”。从机器学习的角度来看,作者身份预测攻击是一个多类分类的问题。首先,攻击者收集一些公开的文件,比如博客。攻击者从每一个文件中提取出刻画写作风格的特征。我们设计的特征包含某些特定刻画写作风格的词的频率、句子的语法结构等。提取出特征后,每一个文件被表示成一个高维的向量。然后攻击者利用机器学习来训练分类器去区分开各个用户。简单的说,给定一个文件,该分类器可以预测该文件的作者。当攻击者得到一个匿名文件时,攻击者首先提取出同样的写作风格特征来将该文件表示成一个高维向量,然后利用提前训练好的分类器来预测该匿名文件的作者。
攻击者可以使用任何分类器,比如说支持向量机。在文献[1]中,我们尝试了各种广泛使用的分类器。我们发现,作者身份可以被准确的预测。具体地说,在我们的实验中,我们考虑十万个用户。给定任意一个用户的文件,我们可以在20%的情况下准确地预测这个文件的作者。对于某些文件而言,我们甚至可以在80%的情况下准确预测文件作者!如果一个攻击者不使用我们的攻击,而是随意猜测,那么该攻击者准确预测作者身份的概率只有十万分之一。另外,在文献[1]中,我们只使用了基本的分类器。攻击者可以利用更强大的分类器(比如深度学习、集成分类器)来进一步提高准确率。
基于社交朋友和行为的属性预测
我们介绍的第二个攻击是基于社交朋友和行为的属性预测攻击[2]。常言道,物以类聚,人以群分。一个用户的属性和该用户的朋友的属性息息相关。举例说,如果一个用户一半的朋友毕业于加州大学伯克利分校,那么该用户很大可能也是毕业于加州大学伯克利分校。另外如果一个用户喜欢的应用App大部分被中国人喜欢,那么该用户也很有可能来自于中国。基于这些观察,我们提出了利用用户的朋友和行为数据来预测用户的隐私属性。
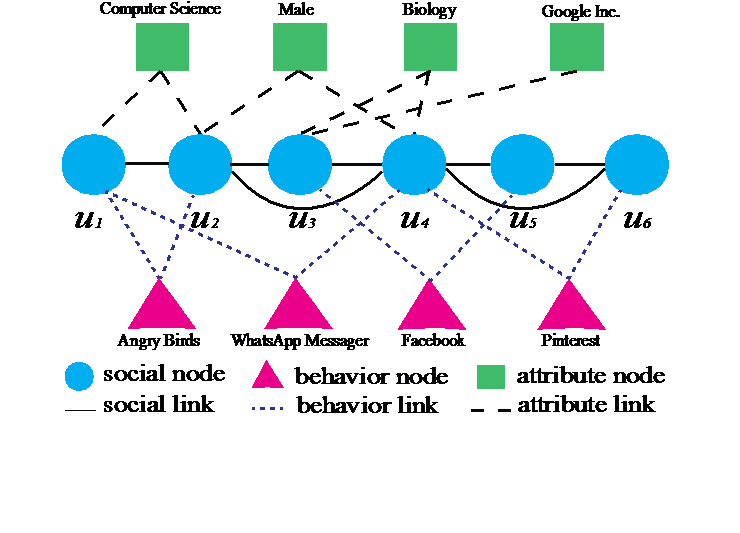
图 1 社交-行为-属性异构图
结合朋友和行为面临很大的挑战,因为这两种数据有天壤之别。为了解决这个挑战,我们提出了一个社交-行为-属性的异构图模型,把朋友、行为和属性这三种迥然不同的数据结合在一起。图1是一个社交-行为-属性的异构图例子。一个社交-行为-属性的异构图有三种类型的节点,分别对应用户、行为对象和属性值。相应的,一个社交-行为-属性的异构图有三种类型的边,分别是用户之间的边、用户和属性值之间的边、和用户与行为对象之间的边。用户和属性值之间的边表示该用户有该属性值。用户和行为对象之间的边表示该用户对该对象做出了某种行为,比如如果一个行为对象是一个移动App,那么行为可以是喜欢、评论。基于社交-行为-属性的异构图模型,我们提出了一个新的基于图挖掘的攻击算法。对于一个目标用户,我们的算法通过分析社交-行为-属性异构图的结构,得出每个属性值属于这个用户的可能性,然后预测该目标用户的属性值。
我们在多于一百万Google用户的数据集上测试了我们的攻击算法。我们的数据中包含了用户的Google+朋友、属性值、以及喜欢过或者评论过的Google Play上的移动App、书、电影等。结果显示,我们的攻击算法可以在大约60%的情况下准确预测一个用户所居住的城市。对于某些用户,准确率甚至可以达到90%。
参考文献:
[1]Arvind Narayanan,Hristo Paskov,Neil Zhenqiang Gong,John Bethencourt,Richard Shin,Emil Stefanov,Dawn Song.“On the Feasibility of Internet-Scale Author Identification”. In IEEE Symposiumon Security&Privacy,2012.
[2]Neil Zhenqiang Gong,Bin Liu.“You are Who You Know and How You Behave:Attribute Inference Attacks via Users‘ Social Friends and Behaviors”. In USENIX Security Symposium,2016.
作者介绍:

Neil Gong 2010年本科毕业于中国科学技术大学计算机系,2015年博士毕业于加州大学伯克利分校,师从国际著名计算机安全科学家Dawn Song。Neil Gong目前是爱荷华州立大学电子和计算机工程系助理教授。Neil Gong的研究方向主要包括社交网络中的安全、隐私、以及挖掘,用户认证,以及移动计算中的安全、隐私、以及挖据。Neil Gong的研究方法涉及大规模图挖掘、机器学习、自然语言处理、以及应用密码学。




